Аварийное восстановление как услуга
Статья
Время на прочтение: 5 минут
DRaaS (DR) — сервис аварийного восстановления IT-инфраструктуры после программных и аппаратных сбоев, техногенных аварий, потери, повреждения данных из-за вредоносного ПО и человеческого фактора. Классическая модель требует физического резервирования в дублирующем ЦОДе или на собственной площадке. Модель аварийного восстановления как сервиса использует технологию репликации ИТ-инфраструктуры в облако. Об этой модели мы и поговорим.
Эффективность DRaaS определяют два параметра — RTO и RPO.
RTO — аббревиатура термина recovery time objective, который дословно переводится как «плановое время восстановления». Это показатель скорости восстановления системы. Другими словами, если RTO заявлен три часа, инфраструктура заработает в течение трех часов.
RPO или recovery point objective — промежуток времени с допустимой потерей данных. То есть, RPO три часа допускает потерю данных не более чем за три часа до инцидента. Не факт, что в результате сбоя будут утеряны данные за все три часа. Может быть только за 10 или 30 минут, однако RPO определяет максимально допустимые значения.
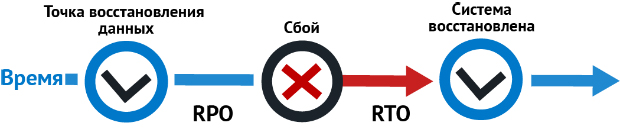
Чем меньше RTO и RPO, тем дороже DRaaS. Система, которая восстанавливается в течение нескольких секунд и теряет данные за 1-5 минут до сбоя, требует дублирования ресурсов и технологии синхронной репликации. Это сложное и дорогое решение. Для некоторых бизнесов его стоимость превысит убытки от простоя.
Для иллюстрации разберем пример с отказом веб-сервера. Допустим, из-за отказа веб-сервера сайт клининговой компании не работал 8 часов. У сайта имиджевая задача, он не является основным каналом продаж. Пока сайт не работал, компания в нормальном режиме обслуживала текущие контракты, а менеджеры обзванивали «теплые базы» и собирали заявки по телефону. Доходы не упали.
Отказ веб-сервера интернет-магазина, особенно во время распродажи, приведет к серьезным убыткам: сайт останется без посетителей, бизнес — без покупателей. Чистый денежный поток закономерно снизится.
Одни и те же сбои в разных бизнесах ведут к разным результатам. Чтобы найти баланс стоимости и эффективности DRaaS в каждом конкретном случае, оценивают:
По результатам определяется, как вероятные потери соотносятся с конкретными показателями RTO и RPO. Исходя из соотношения выбирают одно из трех DR-решений.
1. Бэкап в облачное хранилище по заданному расписанию. Это может быть 1 раз в 24, 12, 6 часов. Расписание бэкапов и запуск восстановления настраиваются непосредственно в консоли управления резервным копированием. Облачный репозиторий развернут в дата-центре уровня Tier III с дублированием сетевых компонентов. Получается так же надежно, как в резервном ЦОДе, но дешевле, потому что в облаке.
Схема проста: система создает архив виртуальной машины (ВМ) и сохраняет дубликат в репозитории. При сбое из облачного хранилища восстанавливается последняя из сохраненных копий. На распаковку данных или архива ВМ уходит какое-то время. Время нужно и на запуск. Именно поэтому у технологии бэкапов самый большой показатель RTO — несколько часов.
Бэкапы в облачное хранилище — самое недорогое решение с оплатой за использованные ресурсы. Оно подходит для некритичных к простою сервисов и компаний, чья деятельность слабо коррелирует с надежностью цифровых сред и инструментов.
2. Асинхронная репликация — более продвинутый вариант Disaster Recovery DR. По этой схеме каждые несколько минут копии виртуальных машин отправляются на резервную площадку. Настройками копирования и восстановления системы клиент управляет самостоятельно. Зная допустимый объем потери данных, он задает RPO в политике репликации. RTO этого решения в реализации Nubes составляет от 30 минут, что удовлетворяет требованиям большей части критичных сервисов.
Аварийное восстановление DR по схеме асинхронной репликации мы реализуем на решениях VMware vCloud Availability и Veeam Cloud Connect Replication. В первом случае для управления репликацией используется консоль Cloud Director. Во втором — специальный модуль Veeam с управлением через веб-панель.
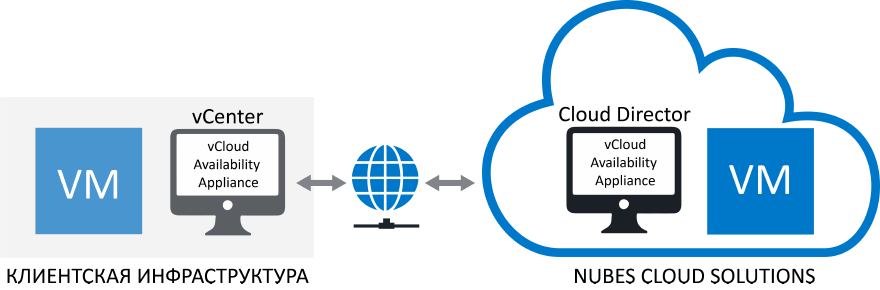
3. Синхронная репликация поддерживает зеркалирование на уровне гипервизора с решением VMware vSphere или на уровне СХД с инструментарием NetApp. Решение разворачивается в облаках двух дата-центров уровняс Tier III. Данные передаются непрерывно, синхронно с работой виртуальных машин на основной площадке. Таким образом, в любой момент времени на дублирующей платформе есть актуальная копия ВМ.
По сути, это единственное по-настоящему катастрофоустойчивое решение проблем с электропитанием, природными катаклизмами, пожарами и сбоями из-за кибер-угроз. Благодаря RTO 2,5 минуты, DRaaS по схеме синхронной репликации подходит банкам, крупным ИТ-компаниям, медицинским организациям, госучреждениям и аналитическим платформам, оперирующим BigData.
Как видите, выбор модели, решений и настроек DRaaS — дело тонкое и деликатное. Здесь нет единой схемы или базового шаблона. Каждый параметр подбирается под специфику, масштаб, бюджет и бизнес-сервисы компании. Есть только одно очевидное правило — чем сложней IT-инфраструктура, тем больше степеней защиты должен обеспечивать сервис аварийного восстановления. Наша компания готова предложить индивидуальный подход к оценке бизнес-критичных процессов, расчету метрик и выбору экономически рентабельного DR решения.