Как организовать катастрофоустойчивое корпоративное облако
Статья
Время на прочтение: 5 минут
Спровоцировать отказ корпоративного облака могут совершенно разные факторы. В большинстве случаев это поломки оборудования, пожары, изъятие и повреждение сервера, а также массовые ошибки в сети хранения или сбой кластера SDS. Cбои возможны как на аппаратном, так и на программном уровне, поэтому говоря об катастрофоустойчивости облака, мы будем говорить об устойчивости трех его компонентов: физической архитектуры, СХД и приложений.
Уровень физической инфраструктуры — базовый. В ЦОД Tier III он обеспечивается за счет, как минимум, двух энерговводов и резервирования активного оборудования по схеме N+1. Свою роль играет и оборудование, на котором разворачиваются облака. Облака Nubes, например, работают на 4-сокетных серверах с процессорами Intel Gold Хeon 6254 3,1 ГГц, СХД Netapp с подключением 16-32 Гб, сетевом оборудовании Cisco и управляющих коммутаторах корпоративного класса Brocade, и развернуты в двух ЦОД уровня Tier III. При этом основные элементы системы (хосты, SAN-свитчи и пр.) на каждой из площадок продублированы.
В целом Tier III обеспечивает уровень отказоустойчивости физической инфраструктуры вплоть до 99,982%, что в пересчете на часы составляет не более 1,6 часа в год.
Катастрофоустойчивость облака на уровне СХД — устойчивость на аппаратно-программном уровне. Она реализуется на базе СХД и VMware vSphere с синхронной репликацией на дублирующую площадку. Работает это так: одна половина СХД находится в одном ЦОД Tier III, а вторая — в другом, такого же уровня. Обе части работают синхронно и данные одномоментно пишутся в одну и другую СХД, поэтому во втором ЦОД в любой момент времени есть идентичная копия виртуальных машин (ВМ) облака. И если в одном из дата-центров происходит сбой из-за отказа питания, сбоя контроллера, дисковых ошибок или повреждения канала связи, на резервной площадке инициируется перезапуск, после которого виртуальные машины начинают работать с того места, где случился сбой.
Катастрофоустойчивость корпоративных облаков на этом уровне мы реализуем через сервис Metrocluster. В случае аварии он сохраняет 100% данных, то есть RPO:0. Однако показатели RTO (допустимое время восстановления данных) зависят от типа сбоя. Если это просто отказ физического оборудования на основной площадке, то RTO составит 2,5 минуты. При тотальном отказе базового ЦОДа на перезапуск операционной системы, виртуальных машин и восстановление данных потребуется порядка 15 минут.
Если взять за основу облака на базе VMware, для облачной катастрофоустойчивости можно использовать прикладные решения для резервного копирования и репликации. Мы используем vCloud Availability и Veeam Cloud Connect, которые обеспечивают репликацию на уровне ПО. При правильно настроенной репликации в определенные временные промежутки в основной и дублирующей инфраструктуре работают две идентичные ВМ. Таким образом, в случае аварии на основной площадке, на резервной можно развернуть готовые к запуску реплицированные виртуальные машины.
VMware vCloud Availability поддерживает доступность приложений, сокращая время аварийного простоя во время аварий.
В рамках решения для текущего облачного узла настраивается стабильный канал репликации с резервным узлом в физической или облачной среде. Чтобы обеспечить защиту от отказа основной инфраструктуры, в клиентском vCenter разворачивается функция vCloud Availability и подключается к vCloud Availability провайдера. В панели управления клиент может выбрать исходную и целевую VDC, на которую будет идти репликация, настроить RPO, политику хранения, количество точек восстановления и период. После этого выбранная виртуальная машина начинает реплицироваться на резервную площадку с заданной скоростью RPO. Чтобы запустить реплику, достаточно выбрать точку восстановления и инициировать процесс.
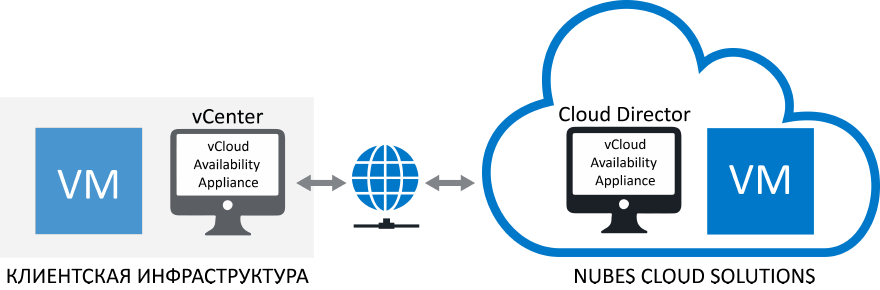
Кстати, VMware vCloud Availability используется не только для защиты корпоративных облаков от сбоев, но и при миграции. В последнем варианте выбранный ресурс полностью и без простоя перемещается из одной среды в другую.
Решение Veeam Cloud Connect Replication настраивает репликацию виртуальных машин и запускает сохраненные реплики в облаке провайдера. В нашем случае — в облаке Nubes, развернутом в дата-центре уровня Tier III. При этом реплики доступны через панель Cloud Director, а инструмент позволяет разворачивать как отдельные реплицированные виртуальные машины с Microsoft SQL, Exchange, Active Directory и Oracle, так и всю инфраструктуру в рамках Failover Plan. Важно, что при восстановлении отдельных виртуальных машин сервис сохраняет связность между ВМ, работающими на основной площадке и ВМ в облаке провайдера.

Для настройки катастрофоустойчивости облака с помощью Veeam Cloud Connect Replication у клиента должен быть отдельный модуль Veeam Backup & Replication. Как и в случае с VMware vCloud Availability, настройки и реплики управляются через веб-панель.
Устойчивость корпоративного облака складывается из устойчивости всех компонентов системы. Нельзя положиться на одну только резервированную физическую инфраструктуру или асинхронную репликацию. Чтобы добиться максимальной стабильности и бесперебойной работы облака, нужно шаг за шагом пройти все уровни, на каждом оценить и закрыть потенциальные риски. Только в этом случае мы можем говорить о действительно катастрофоустойчивом облаке, которое сохраняет параметры доступности и производительности при отказе одного или нескольких фрагментов инфраструктуры.